Primární účel DNS (Domain Name System) je zprostředkovat překlad doménových jmen na adresy v síti. Ve zjednodušené formě – klient generuje dotazy a server poskytuje odpovědi. Jako takový tvoří DNS jednu z důležitých služeb v IP sítích. Ve většině případů začíná komunikace na internetu právě DNS dotazem. Stopy této komunikace lze nalézt na různých úrovních DNS hierarchie. Analýzou těchto stop (DNS dotazů) lze získat užitečné informace o stavu sítě a chování jejích uživatelů.
Sběr DNS dat
DNS provoz je potřeba extrahovat z celkového síťového provozu. Převážná část DNS provozu je přenášena nefragmentovanými UDP pakety. Abychom získali pokud možno celistvý pohled na přenášená data, je nutné u zbylého provozu provést defragmentaci paketů a provést rekonstrukci TCP spojení. Je také nutné se vypořádat s poškozenými pakety nebo nedokončenými datovými přenosy.
V DNS provozu na serverech obsluhujících .cz TLD převládá síťový protokol IPv4. V závislosti na objemu provozu a umístění serveru se jeho zastoupení pohybuje kolem 90 %. Výjimku tvoří server akuma, umístěný v Japonsku, u kterého je poměr IPv4/IPv6 převrácený. Na transportní vrstvě dominuje UDP.
Aplikace DNS Collector zjednodušuje zpracování DNS provozu tím, že je schopna poslouchat provoz na několika síťových rozhraních současně. V současné době k tomu využívá knihovnu libpcap. Zachycený síťový provoz je defragmentován. V případě TCP provozu je sledováno správné ustanovení a ukončení TCP relace. Přerušená TCP spojení nebo neúplné pakety jsou po čase zahozeny. Zrekonstruované surové (tak jak jsou přenášené po síti) DNS pakety jsou v závislosti na použité síťové a transportní vrstvě opatřeny daty z IPv4/IPv6 a UDP/TCP hlaviček. Takto připravená data jsou předána ke zpracování do modulů.
DNS Collector umožňuje zpracovávat také archivovaný provoz uložený v souborech na disku (ve formátu podporovaném knihovnou libpcap). V tom případě pak ale není možné současně zpracovávat archivovaný provoz s živým provozem ze síťových rozhraní. V současné době také není také možné zpracovávat více archivů (souborů) současně, protože doposud nebyl implementován mechanismus řazení paketů podle časových značek uložených v souborech. V případě, že je potřeba zpracovat více archivů současně, je nutné použít externí aplikaci jako je například mergecap nebo PCAPMerger.
Zpracování provozu v modulech
Modul je funkční jednotka, která se zabývá zpracováním surových DNS dat. Tyto data mu připravuje DNS Collector způsobem zmíněným v předcházející části. Moduly představují funkční abstrakci, umožňující izolovat jednotlivé činnosti nad DNS daty. Moduly si udržují vlastní kontexty, mohou tedy pracovat nezávisle na ostatních modulech.
Moduly lze nahrávat nebo uvolňovat za běhu celé aplikace. V porovnání se samostatnými aplikacemi provádějícími ekvivalentní činnost mají moduly výhodu menší režie. Všechny moduly totiž společně sdílí společnou vrstvu, která se stará o přípravu vstupních dat. Tato vrstva by v případě samostatných procesů musela existovat ve všech procesech.
DNS Collector neposkytuje žádné rozhraní pro parsování surových DNS dat. V závislosti na povaze zpracovávaných dat je možné implementovat vlastní jednoduchý parser DNS paketu, nebo v případě složitějších operací použít některou z existujících knihoven, jako je například ldns.
Detektor anomálií
Tento modul vychází ze samostatného projektu detektoru DNS anomálií. Původní samostatná aplikace prováděla statistickou analýzu části DNS provozu, která byla dostupná v úplných UDP paketech. Na základě vzájemné podobnosti zjištěných vzorů pak posuzovala, zda je provoz „normální“. Je nutné upozornit, že se jedná o hodnocení ve smyslu: normální je převažující chování. V tomto smyslu anomálie nemusí být nutně škodlivé, pouze se něčím vymykají charakteristice většiny. Díky použití v DNS Collectoru je možné zpracovávat data pocházející z fragmentovaných paketů a dat přenášených přes TCP.
Výstupem tohoto modulu je textové hlášení o detekovaných anomálních identifikátorech. Volitelným výstupem jsou soubory vykreslující výskyt detekovaných anomálií ve formátu vhodném pro zpracování gnuplotem.
Na následujících obrázcích je ukázka několika typů detekovaných anomálií. Data byla zachytávána a analyzována v desetiminutových intervalech 1. října na serveru dns-b-01. Grafy zobrazují zastoupení anomálního provozu v poměru k celkovém provozu. IP adresy jsou záměrně nahrazeny.
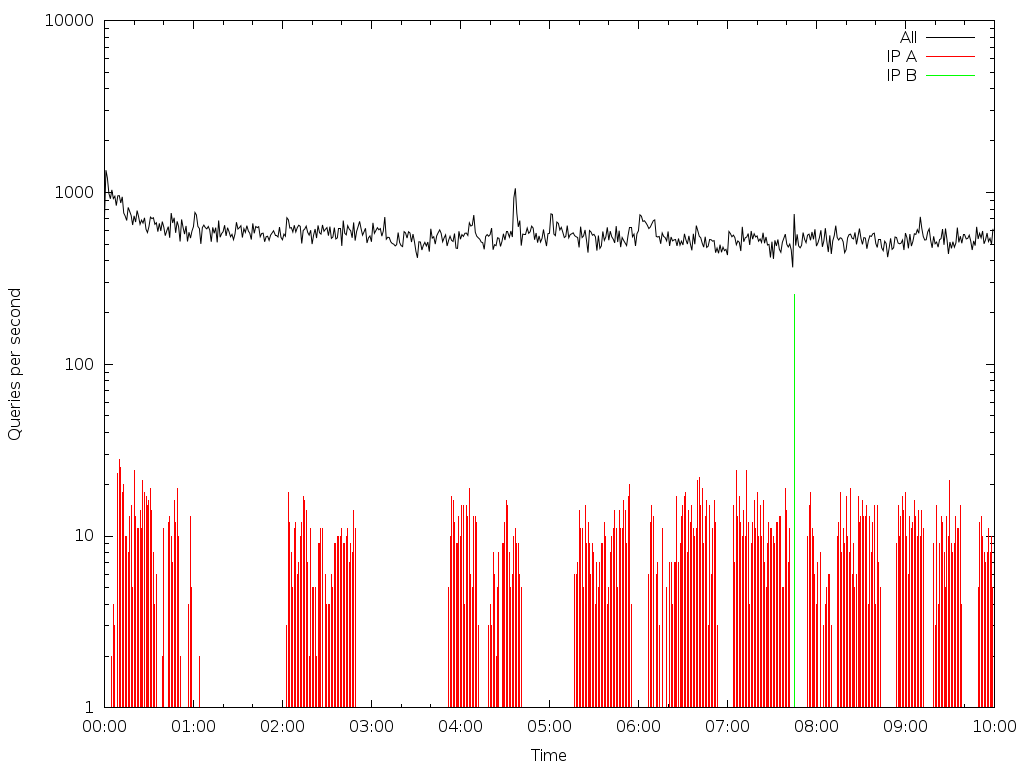
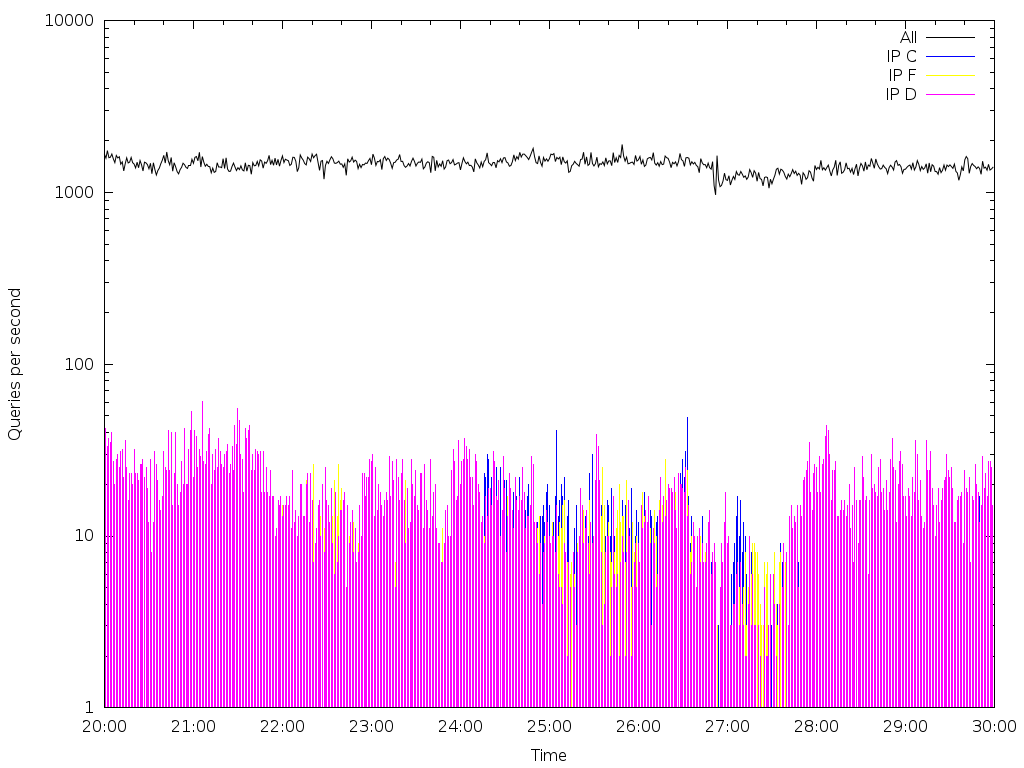
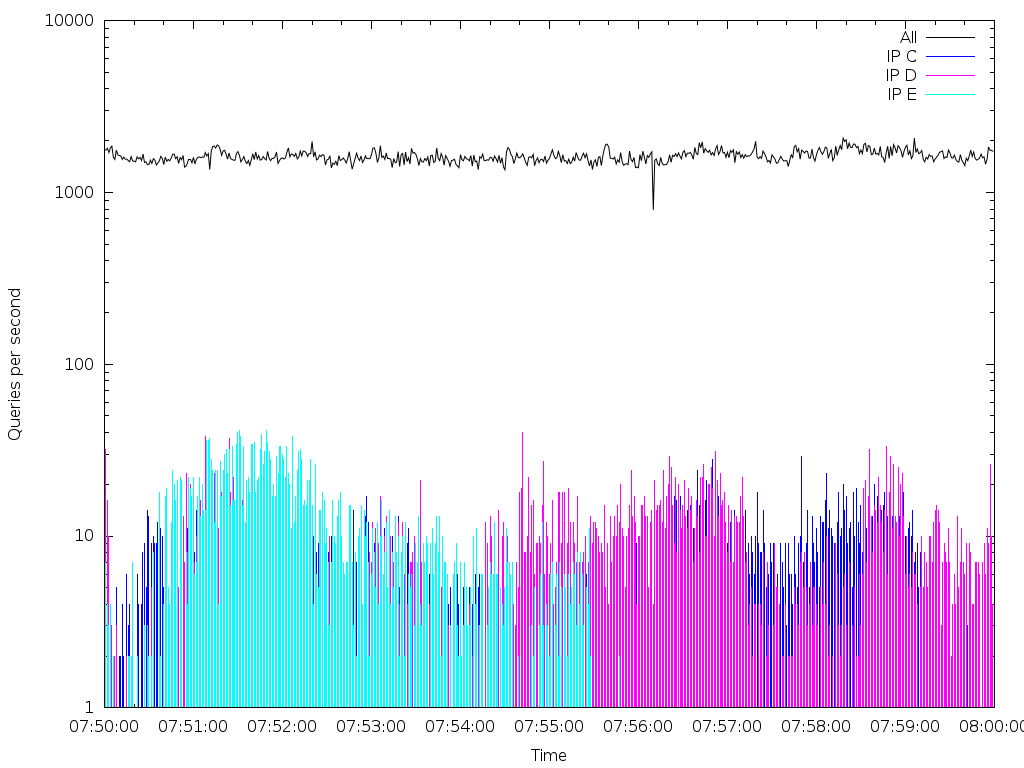

Na grafech je zobrazeno zastoupení provozu označeného jako anomální:
IP A – hromadné rozesílání emailů, provoz obsahuje dotazy na MX a adresy mailserverů
IP B – opakovaný dotaz se stejným ID v krátkém intervalu (300x během 2ms)
IP C, D, F, G – rekurzivní resolvery
IP E – DKIM spam-filter
IP H – opakované dotazy na adresy tří nameserverů, postupně se zvyšující ID dotazů
Spouštění skriptů v Pythonu
Ne každá analýza si zaslouží samostatný modul psaný v C. V případech, kdy není jisté, zda bude výsledek použitelný, je výhodnější použít jazyk s méně pracnou správou paměti a přívětivější správou datových struktur, který je vhodnější pro prototypování. Teprve v případě, kdy je ověřeno, že testovaný postup bude fungovat, bude nutné algoritmus přepsat do C nebo C++.
Pro účely rychlého návrhu slouží modul pro spouštění pythoních skriptů. Modul implementuje wrapper pro rozhraní DNS Collectoru. Toto rozhraní je pak možné využívat ve spouštěném skriptu. Samotný modul volá interpret jazyka Python (libpython). Kód wrapperu obaluje předávané C-čkové struktury a vytváří z nich PyObjecty. Za cenu snížení výkonu aplikace, v důsledku obalování datových struktur, je možné využívat všechny výhody dynamicky typovaného interpretovaného jazyka s automatickou správou paměti. Surová DNS data je možné v Pythonu zpracovávat pomocí pyLDNS (wrapper okolo LDNS).
Použití tohoto modulu není pro jiné účely, než je testování, doporučeno. Důvodem je samotná knihovna libpython. Tato knihovna nepodporuje více samostatných interpretů v rámci jednoho procesu. Libpython nepoužívá kontext pro předávání konfigurace interpretru; kontext interpretu existuje jako globální struktura(y) v prostoru procesu. Libpython sice implementuje něco, čemu říká sub-interpreter, ale jak sami tvůrci v dokumentaci uvádí, izolace těchto „pod-interpretrů“ není úplná. Při použití funkcí z nízkoúrovňových operací připouštějí jejich vzájemné ovlivňování.
Konfigurace
DNS Collector je možné spouštět na popředí z příkazové řádky. V tom případě je možné konfigurovat a používat pouze jedno síťové rozhraní či archiv a jeden modul. Tento režim slouží zejména k testování modulů nebo ke spouštění v dávkovém režimu pro postupné zpracování více archivů. Primární určení DNS Collectoru je být spuštěn jako daemon pro monitorování DNS provozu. V tomto případě je vhodnější používat konfigurační soubor, ve kterém je možné současně specifikovat nastavení několika síťových rozhraní společně s několika moduly.
Experimentální konfigurace NETCONFem
Pro použití ve vzdálených zařízeních je experimentálně implementována možnost konfigurace pomocí protokolu NETCONF. NETCONF je protokol založený na XML, umožňující konfiguraci síťových zařízení. Funkce NETCONF serveru je naprogramována s využitím knihovny libnetconf. Tato knihovna implementuje NETCONF server a klient a bezpečný komunikační SSH kanál.
DNS Collector na listopadové konferenci CZ.NIC
Pokud vás tento projekt zaujal a máte k němu otázky, můžete samozřejmě využít komentářového formuláře. Jestli se ale chcete dozvědět více a zeptat se přímo, doporučil bych vám, abyste si udělali čas na naši konferenci Internet a Technologie 13.2 (30. 11., MFF UK, Praha), v jejímž již brzy zveřejněném programu prezentace na toto téma bude.
Karel Slaný