Viacero používateľov CZ.NIC aukcií si už od ich spustenia mohlo všímať neprehľadnosť ponúkaných domén. Domény bývali zoradené buď abecedne alebo na základe dĺžky. Nepomáhal ani fakt, že pri abecednom radení sú čísla zaradené na začiatku. Nových návštevníkov mohlo nepríjemne prekvapiť, ak po otvorení zoznamu aukcií videli namiesto zaujímavých doménových mien len nezmyselné postupnosti znakov. Neprekvapilo by ma, ak by časť návštevníkov po tejto skúsenosti web aukcií dlhší čas nenavštívila. Preto sme sa situácii začali venovať a krátko na to sme spustili znevýhodnenie domén obsahujúcich vysoký pomer čísel a spojovníkov. V októbri sme sa začali venovať problému viac do hĺbky a v rámci svojej diplomovej práce som začal skúmať, na základe akých kritérií je možné doménu ohodnotiť.
Už na začiatku sme sa zhodli, že aukcie domén majú slúžiť predovšetkým ľuďom, ktorí chcú vydraženú doménu používať a nie obchodníkom s doménami, dražiacich domény len za účelom zisku. Preto sme zamietli zaužívané postupy rôznych ohodnocovacích stránok, ktoré sledujú primárne históriu domény spoločne s na nej sídliacim webom. Rozhodli sme sa nesledovať počet spätných odkazov na doménu na internete, dobu od jej prvej registrácie, počet registrácií či dokonca návštevnosť alebo objem DNS prevádzky. Predpokladáme, že nášho cieľového používateľa tieto hodnoty nemusia zaujímať a dokonca môže byť predchádzajúca popularita domény niekedy na škodu. Z tohto dôvodu sme sa minimálne zo začiatku sústredili čisto na doménové meno. Hlavným cieľom prvého vylepšenia bolo uprednostniť prémiovejšie domény, teda domény ideálne zložené z jedného, prípadne dvoch dostatočne všeobecných a známych slov. Tie najhodnotnejšie popisujú celú kategóriu, ako napríklad „knihy.cz“ či „obuv.cz“.
Extrakcia a hodnotenie slov
Prvým krokom tohto riešenia bolo z názvu domény extrahovať slová. To sa na prvý pohľad zdalo ako jednoduchá úloha, no keďže doména je relatívne krátky text bez diakritiky, ktorý často obsahuje aj nespisovné slová a skratky, nie je jednoduché určiť, čo pôvodný držiteľ myslel. Nepomáha ani fakt, že je občas možné názov rozkľúčovať viacerými spôsobmi. Tento krok si zatiaľ vyžiadal najviac času a experimentovania s rôznymi prístupmi. Nateraz som sa rozhodol využiť vyhľadávanie slov v slovníkoch použitím Aho-Corasick algoritmu. Vybraný algoritmus je pomocou slovníkov schopný nájsť všetky slová nachádzajúce sa v doméne. Keďže je zo všetkých nájdených slov potrebné vybrať ideálne správnu kombináciu, pripravil som algoritmus, ktorý má za úlohu vybrať čo najvhodnejšiu kombináciu slov. Systém je nateraz pripravený na vyhľadávanie slov v českom, anglickom a slovenskom jazyku, pričom umožňuje jednoduché pridanie ďalších jazykov.
Popularita slov
Popri riešení extrakcie slov som prešiel k úlohe, ako jednotlivé slová ohodnotiť. Keďže využitie nástrojov hodnotiacich vyhľadávanosť kľúčových slov nebolo reálne pre tisícky slov súčasne, zvolil som meranie početnosti výskytu slova v jazyku. Úlohou bolo spočítať výskyty jednotlivých slov v datasete textov zozbieraných z internetu. Vybraný dataset mOSCAR obsahoval pre jeden jazyk desiatky gigabajtov textu z 3-4 miliónov vzoriek webov. Tieto texty som prečistil a pripravil pre potreby ohodnocovania. Prečistenie zahŕňalo odstránenie diakritiky, interpunkcie a špeciálnych znakov. Ďalšia príprava bola zložená zo spojenia samostatných viet a odstavcov každého webu do súvislého textu a následného rozdelenia textu na slová. Po tejto úprave datasetu som prešiel k počítaniu výskytov slov v jednotlivých vzorkách. Výsledkom bol celkový počet výskytov slov pre celý jazyk. Na tieto výsledky som aplikoval funkciu logaritmu, aby som zmiernil exponenciálne rozloženie výskytov slov. Následne som na tieto hodnoty aplikoval min-max normalizáciu, aby bol počet výskytov jedného slova reprezentovaný hodnotou v rozsahu 0-1. Zoznamy používanosti slov sú vytvorené pre každý zahrnutý jazyk samostatne. Každému zoznamu je možné prideliť váhu, ktorá určuje, aké jazyky má systém uprednostňovať. Momentálne systém na základe dát mierne zvýhodňuje češtinu.
Voľba kombinácie extrahovaných slov
Keďže pri extrakcii slov existuje viacero možností, ktoré môžu byť považované za správne, sú pre každú doménu vytvorené viaceré kombinácie slov dvomi metódami. Pred začiatkom zostavovania kombinácií je každému nájdenému slovu priradená popularita.
V prvej metóde je vybraných n najpopulárnejších slov, z ktorých sú následne rekurzívne zostavované možné kombinácie slov tak, aby sa slová navzájom neprekrývali a neopakovali. Pri tomto prístupe som sa však potreboval vysporiadať s tým, že jednoznakové alebo dvojznakové slová ako spojky a predložky sú v každom jazyku používané najčastejšie. To by spôsobovalo, že napríklad slovo „krabica“ by mohlo byť nesprávne rozdelené na dve slová „krabic“ „a“ pre vysokú popularitu spojky „a“. Preto bola pre výber najvhodnejšej kombinácie slov v doméne popularita týchto veľmi krátkych slov mierne znížená. Druhou metódou je postupný výber čo najdlhších slov, rovnako s podmienkou, aby sa slová neprekrývali a neopakovali. V tejto metóde je vykonaných n iterácií, pričom je v každej iterácii vytvorená jedna kombinácia. Po každej iterácii je zo zoznamu testovaných slov odobrané najdlhšie slovo, čo umožňuje vznik nových kombinácií s kratšími slovami. Po aplikovaní oboch metód sú vytvorené kombinácie ohodnotené a následne je ako výsledok vybraná kombinácia s najlepším ohodnotením.
Ohodnotenie extrahovaných slov
Po extrakcii slov je možné začať určovať parametre domény. Pre zvolený cieľ uprednostňovania prémiovejších domén je možné určiť, koľko slov doména obsahuje a či sa v doméne nachádzajú aj ďalšie znaky naviac, ktoré žiadne slovo netvoria. Napríklad „ab“ v doméne „abdodavky.cz“ je možné označiť pomerom 7⁄9. Ako tretí parameter je možné použiť priemernú popularitu slov v doméne.
Aby bolo finálne ohodnotenie jednoduchšie je každý parameter domény prevedený na rozsah 0-1. Pre počet slov v doméne je doméne obsahujúcej jedno slovo priradená hodnota 1 a pre vyšší počet slov hodnota postupne klesá. Ohodnotenie počtu znakov nachádzajúcich sa mimo slov je vypočítané z upraveného pomeru znakov v slovách a oproti celkovej dĺžke domény. Hodnota 1 znamená, že sa v doméne okrem slov nenachádza žiadny znak naviac. Nakoniec je podľa popularity jednotlivých slov vypočítaná priemerná popularita slov v doméne. Z týchto troch hodnôt je geometrickým priemerom vypočítané výsledné ohodnotenie jednotlivých kombinácií pri extrakcii slov.
Ohodnotenie parametrov domény
Okrem popísaného hodnotenia extrahovaných slov sú hodnotené aj všeobecné parametre domény. Konkrétne jej dĺžka, počet čísel a počet spojovníkov. Tieto parametre sú taktiež prevedené na rozsah 0-1.
Prístup k hodnoteniu parametrov
V tejto verzii bol pre ohodnotenie domén zvolený prístup, kde je pre každý z parametrov definovaná nelineárna funkcia zabezpečujúca prevod jeho hodnoty na rozsah 0-1. Voľbou jej tvaru je už samotným parametrom udeľované určité ohodnotenie. Napríklad pre počet slov v rozsahu 1 až 3 je výstup funkcie podstatne bližšie k 1 ako pre vyššie počty slov. Tvary funkcií sú vyberané na základe teoretických poznatkov o hodnote domén. Tento prístup bol zvolený hlavne pre otestovanie konceptu a tiež z dôvodu momentálneho nedostatku dát pre použitie neurónovej siete, ktorá by mohla tento krok eliminovať. Každému z parametrov je pridelená taktiež manuálne zvolená váha, ktorá je následne zohľadnená vo finálnom ohodnotení domény. Finálne ohodnotenie je váženým geometrickým priemerom všetkých parametrov, tiež v rozsahu 0-1. Podľa tohto ohodnotenia môžu byť nakoniec domény v aukciách zoradené.
Detail hodnotenia
V priloženej tabuľke sa nachádzajú spomínané parametre finálneho ohodnotenia. Prvé dva stĺpce obsahujú extrahované slová a ohodnotenie pomeru znakov v slovách oproti celkovej dĺžke. Ďalšie tri stĺpce obsahujú postupne ohodnotenie počtu slov, spojovníkov a čísel. V druhej časti tabuľky sa nachádza priemerná popularita domény, popularita jednotlivých slov, ohodnotenie celkovej dĺžky a nakoniec celkové ohodnotenie domény.
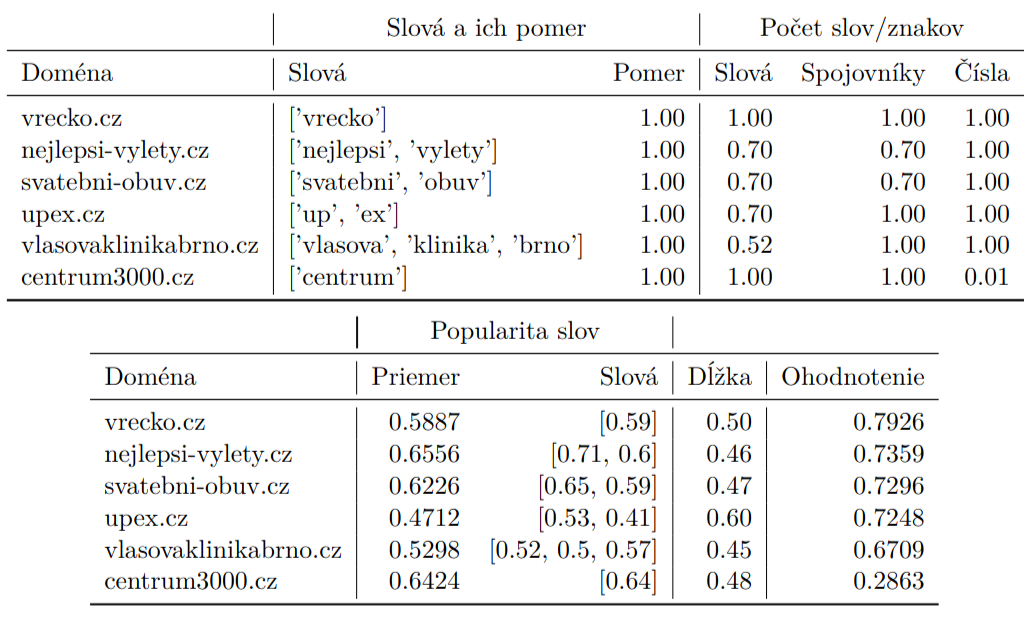
Obrázek 1: Ohodnotenie všetkých parametrov pre výber z domén pripravených na aukciu.
Napojenie na aplikáciu aukcií
Systém pre ohodnocovanie beží ako samostatná aplikácia vo frameworku FastAPI. Jej endpoint pre ohodnotenie je pravidelne volaný z aplikácie aukcií, kde sú týmto spôsobom ohodnocované nové exspirované domény. V požiadavke na ohodnotenie je zaslaný zoznam domén a ich identifikátorov. V odpovedi sú vrátené identifikátory a udelené celkové ohodnotenia domén. Podľa príslušného identifikátoru sú následne ohodnotenia uložené k doménam v databáze aukcií. Pri načítavaní zoznamu v klientskej aplikácii aukcií používateľom, sú do nej zasielané už zoradené domény podľa uloženého ohodnotenia.
Testovanie riešenia
Pre zhodnotenie funkcionality zvoleného postupu boli po implementácií riešenia porovnané jeho výstupy s cenami zatiaľ vydražených domén. Tých bolo v čase testovania približne 3600 s rozsahom cien približne 100 až 150 000 Kč. Ceny domén boli pred porovnávaním normalizované. Po spárovaní každej domény s jej cenou a ohodnotením boli v prvom porovnaní dáta spriemerované podľa výslednej cenovej kategórie (Obr. 3). V druhom porovnaní boli spriemerované podľa výsledného poradia domén v jednotlivých aukciách v určitý deň (výsledné poradie bolo určené finálnou cenou) (Obr. 2). Na výsledkoch je vidieť, že ohodnotenie relatívne dobre odpovedá výsledným cenám priemerovaným podľa poradia, no pre cenové kategórie všetkých vydražených domén nie je až tak výrazné. Do budúcna je cieľom spôsob ohodnotenia ďalej vylepšovať a neskôr zvážiť aj využitie vydražených domén na natrénovanie neurónovej siete.
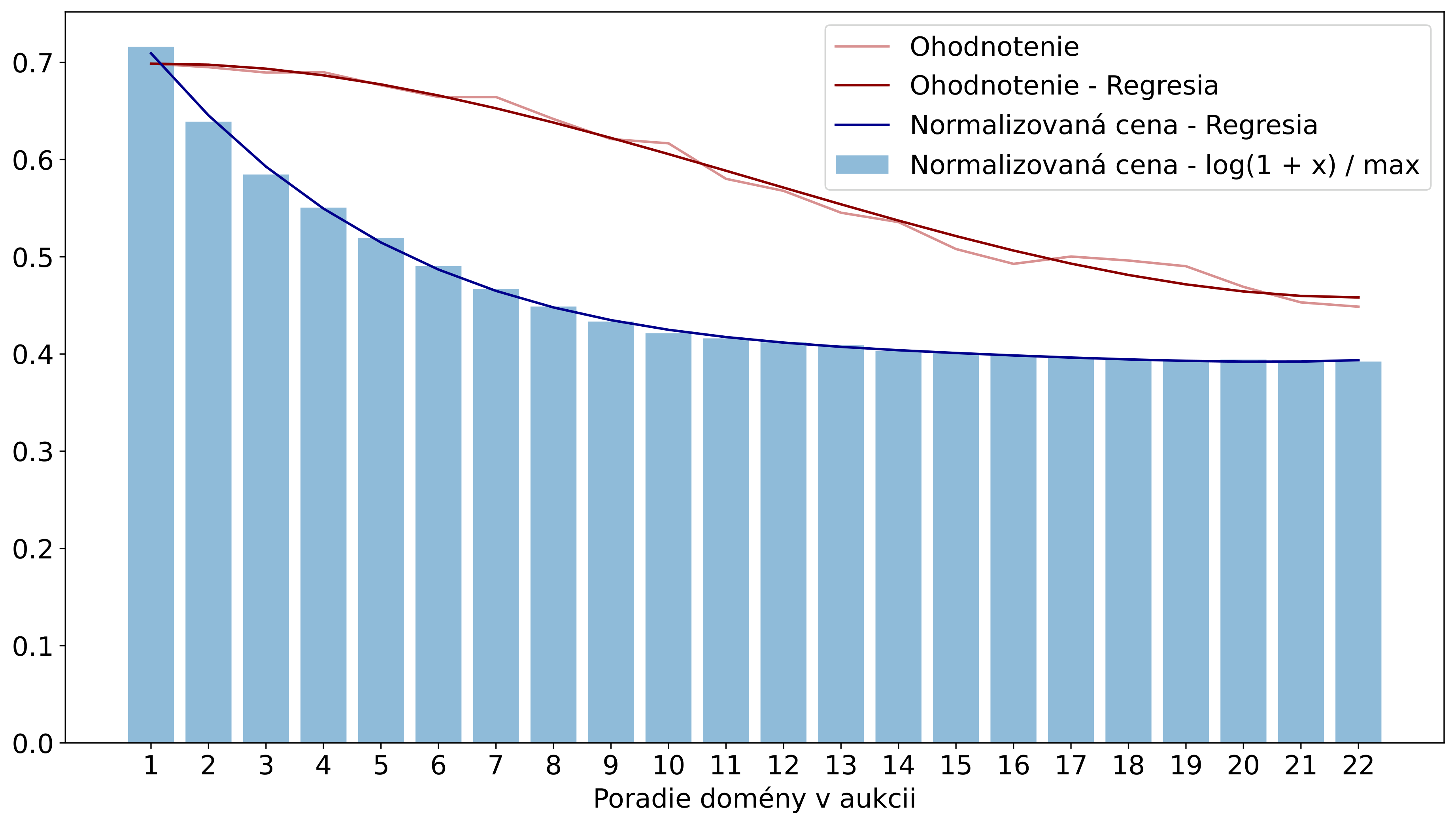
Obrázek 2: Ceny domén a ich ohodnotenia sú spriemerované podľa výsledného poradia v aukcii. Je vidieť, že domény, ktoré končili na vysokých priečkach v aukcii majú priemerne aj vyššie ohodnotenie.
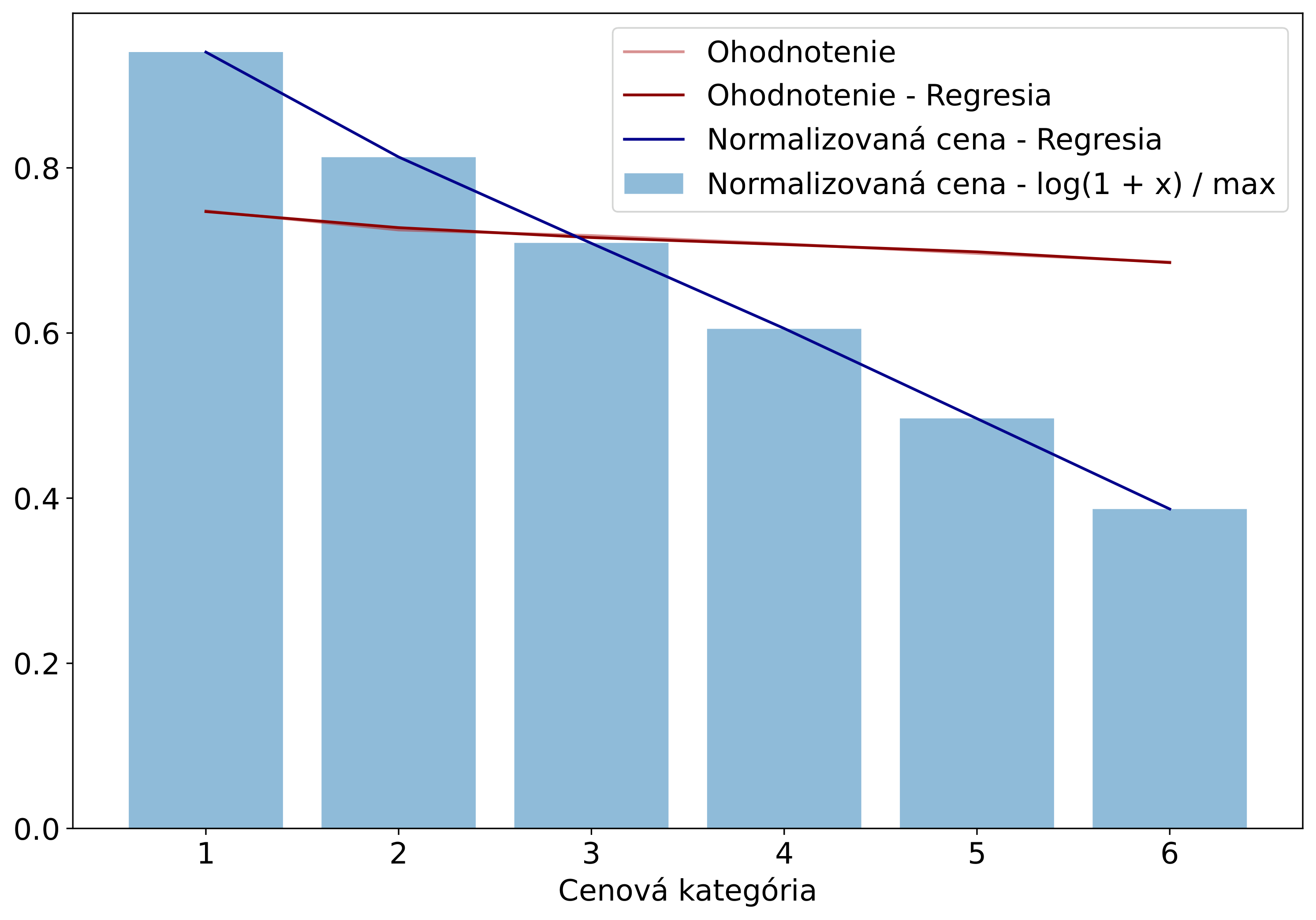
Obrázek 3: Ceny domén a ich ohodnotenia sú spriemerované podľa cenovej kategórie. Je vidieť, že domény s vyššou cenou majú aj mierne vyššie priemerné ohodnotenie, no rozdiel nie je až tak výrazný ako pri rozdelení po jednotlivých priečkach.
Popisované riešenie bolo spustené 10. 2. 2025.
Myslím si, že krok týkající se vyřazení zažitých metrik, byl krok vedle. Tyhle data zajímají většinu současných nakupujících.
Podle mě zbytečná práce. Potenciální kupci hledají obvykle spíš doménové jméno obsahující nějaký konkrétní řetězec, což si mohou ze seznamu s libovolným řazením vybrat pomocí hledání stringu prostředky browseru. Kromě toho dělení slov minusy znamená zpřehlednění, za což by naopak měla být bonifikace. Potlačením podobných „akademických“ aktivit by se za ušetřené náklady možná mohly zlevnit domény.
Za mě super, díky za Vaši práci :) A je minimálně motivující, že se dá psaní diplomové práce spojit s hledáním odpovědí na otázky reálného světa a jejich následnou implementací. 👏
Líbí se mi váš pohled na exspirované domény. Každopádně si myslím, že by tam měla být i volba „zažitých metrik“. Což je to, co zajímá právě mě.
Nelze tam udělat nějaký select aby si lidi mohli vybrat jak ty aukce řadit?